Tidehunter: Re-Architecting Storage for Sustained Blockchain Throughput
Addressing the storage demands that emerge when blockchains operate at sustained, real-world scale


Main Takeaways
- As blockchains mature, storage—not computation—often becomes the first real bottleneck. In sustained, real-world blockchain usage, disk IO can reach its limits well before consensus or execution does.
- General-purpose databases incur significant overhead under blockchain workloads. Write amplification forces many more bytes to be written than applications produce, consuming disk bandwidth and increasing latency.
- Purpose-built storage enables higher, more stable performance at scale. By eliminating unnecessary rewrites and aligning data layout with blockchain access patterns, Tidehunter sustains throughput while reducing latency under long-running load.
Overview
As blockchains mature, performance challenges shift. Early on, the focus is often on consensus, execution, and networking. Over time, as throughput increases and workloads stabilize into sustained, real-world usage, a different set of bottlenecks begins to dominate.
With Sui, we routinely run large-scale stress tests on private clusters to ensure the system continues to meet performance targets as the protocol evolves. These tests are designed not just to measure peak throughput, but to surface early signals of where the system will struggle in the future. One such signal became increasingly clear: disk IO utilization was approaching saturation well before other system resources, even on high-end validator hardware backed by multiple SSDs in RAID-0 configurations.
While disk was not yet the limiting factor, the trend was unmistakable. If Sui is to support sustained high throughput over long periods of time, storage efficiency must improve. Rather than waiting for the disk to become a hard bottleneck, we chose to build a new foundation early.
That foundation is Tidehunter: a storage engine designed specifically for the performance envelope, access patterns, and operational realities of modern blockchains, and a candidate to become the next validator and full-node database for Sui.
From a sensible default to a purpose-built design
Like most blockchain systems, Sui initially adopted RocksDB as its primary key-value store. This was a pragmatic choice. RocksDB is widely used, well understood, and allowed the team to focus on building and shipping the protocol itself.
As Sui scaled and added features, however, we began to encounter limitations that were not a matter of configuration or tuning, but structural mismatches between general-purpose LSM-tree databases and blockchain workloads. We spent significant time optimizing RocksDB parameters, and several members of the team have deep expertise in its internals. Despite that, certain inefficiencies remained unavoidable.
At that point, it became clear that staying ahead of real-world performance requirements would require a different approach. Rather than continuing to push against the constraints of existing open-source designs, we decided to explore what a custom storage engine, built specifically for blockchain workloads, could look like.
Tidehunter was born from that exploration.
The core limitation: Write amplification
The most significant issue we observed with RocksDB was write amplification. In Sui’s production-like workloads, we measured write amplification on the order of 10–12x. In practical terms, this meant that roughly 40 MB/s of application-level writes translated into 400–500 MB/s of disk writes. While this may sound extreme, it is not unusual for LSM-tree systems, and reports of even higher amplification are common in other deployments.
The implication is straightforward but severe: write amplification shrinks your machine. When amplification is 10x, only about 10% of your disk bandwidth is doing useful work. The remaining IO is consumed by internal rewrites and compactions, directly competing with reads for SSD bandwidth.
For blockchain workloads, which are typically write-heavy or close to a 50/50 read-write split, this tradeoff becomes increasingly costly as throughput grows.
Early signals from the load-test cluster
Before diving into Tidehunter’s design, it’s worth grounding this discussion in what we actually observed in practice. Even on high-end test fleets, disk IO utilization approached saturation during sustained load. Application-level writes were relatively modest, yet OS-reported disk write throughput was an order of magnitude higher, a direct manifestation of write amplification.

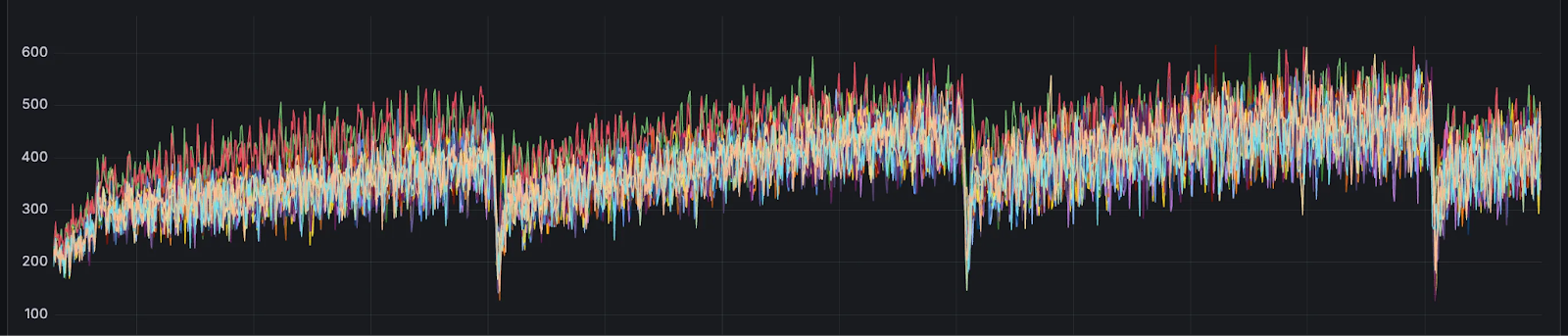
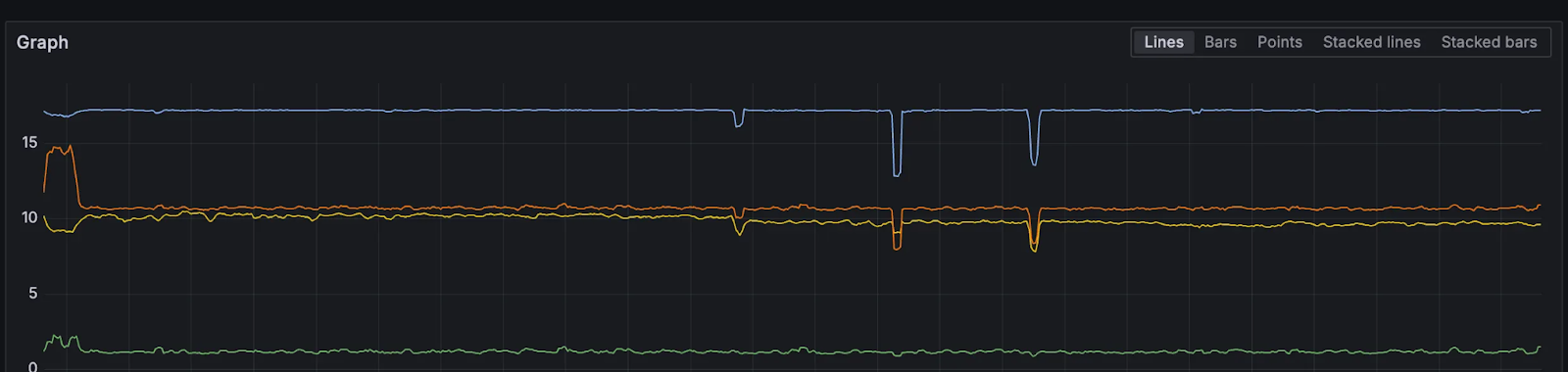
These early signals motivated a deeper rethinking of the storage layer.
Storage patterns in Sui and similar blockchains
Tidehunter is designed around a small number of access patterns that dominate Sui and many other blockchain systems.
First, many tables use uniformly distributed random keys with relatively large values. Transactions, effects, and objects are keyed by cryptographic hashes, which eliminates locality but simplifies correctness and consistency.
Second, blockchains rely heavily on sequential or semi-sequential log-like structures, such as consensus blocks and checkpoints, where writes are primarily append-only, and reads are indexed by monotonically increasing identifiers.
Finally, blockchain workloads tend to be write-intensive, with meaningful read pressure on hot paths. Excessive write amplification in this environment not only wastes disk bandwidth but also directly reduces the system’s ability to serve low-latency reads.
High-throughput, low-contention write path
At the core of Tidehunter is a write path designed to fully utilize modern SSDs without introducing contention. All writes flow through an ultra-fast, lock-free write-ahead log (WAL), capable of sustaining on the order of one million operations per second.
The write pipeline is split into allocation, data copy, and confirmation. Only allocation introduces contention, and even there, the cost is limited to a single atomic counter update. Data copying happens in parallel across writers, allowing throughput to scale cleanly with concurrency.
To minimize overhead on the critical path, Tidehunter uses writable memory-mapped files instead of per-write syscalls. Durability is handled asynchronously by background service threads that manage file growth and periodic syncing. The result is a write path that is highly parallel, predictable under sustained load, and able to saturate disk throughput without becoming CPU-bound.
Minimizing write amplification by design
Reducing write amplification is a first-order design goal in Tidehunter, not an afterthought. Rather than treating the write-ahead log as a transient buffer, Tidehunter reuses the WAL as permanent storage. Values are written once and never copied again; indexes simply reference offsets within the log. This alone eliminates a large class of redundant writes.
Index space is then aggressively sharded, with thousands of shards per table by default. This dramatically reduces per-shard write amplification while enabling high read and write parallelism. In practice, this makes it unnecessary to rely on LSM-tree structures.
For append-heavy tables such as checkpoints and consensus data, Tidehunter applies specialized sharding strategies that intentionally co-locate recent writes into a small number of shards. This yields a key property: write amplification does not increase as the dataset grows, even as historical data accumulates.
Uniform lookup index for low-latency reads
For tables keyed by uniformly distributed hashes, Tidehunter uses a specialized uniform lookup index designed explicitly to reduce read latency on the critical path. Rather than performing multiple small, random index reads, the uniform lookup index leverages the statistical properties of uniformly distributed keys to predict where a key is most likely to reside. It then reads a slightly larger contiguous segment of the index to ensure that the value is almost always found in a single disk round trip.
This approach deliberately trades read throughput for lower read latency. In practice, that tradeoff works well for blockchain workloads. Because Tidehunter largely eliminates write amplification, disk bandwidth that would otherwise be consumed by internal rewrites is instead available for reads. That spare bandwidth allows Tidehunter to amortize slightly larger reads in exchange for significantly lower tail latency.
For latency-sensitive paths, such as transaction execution, object access, and state validation, opting into the uniform lookup index reduces the number of disk round-trips and helps keep read latency predictable even under sustained load.
Direct IO and user space caching
To reduce read latency at scale, Tidehunter combines direct IO with application-aware caching rather than relying on the operating system’s page cache.
Direct IO allows Tidehunter to bypass the OS cache entirely when reading large historical datasets, reducing cache pollution and improving latency predictability. At the same time, Tidehunter maintains its own user-space caches for recent data, where it has better visibility into access patterns and can make more informed eviction decisions.
This approach pairs especially well with Tidehunter’s indexing strategies, which reduce the number of disk round-trips required for lookups. In practice, it leads to lower tail latency and more efficient use of available disk bandwidth.
Efficient pruning of historical data
Validators typically retain only a limited window of historical data, such as the most recent epochs of transactions. Tidehunter makes pruning this data simple and efficient.
Because data is stored directly in WAL segments, removing outdated data is as straightforward as dropping entire log files once they are no longer needed. This avoids the complex and IO-intensive compaction filters required to reclaim space in LSM-tree databases.
As a result, large-scale data deletion becomes fast, predictable, and operationally simple, even when datasets grow very large.
Performance results
Across a range of workloads designed to mirror Sui’s real access patterns, Tidehunter consistently delivers higher throughput and lower latency than RocksDB while using significantly less disk bandwidth. The most immediate and visible improvement comes from the near-elimination of write amplification: disk write throughput closely tracks application-level writes, leaving substantially more IO headroom for reads. As load increases, this translates into more stable performance, lower tail latency, and fewer IO-induced stalls.
These gains show up both in controlled benchmarks and in full Sui validator runs, indicating that the improvements are not artifacts of synthetic tests but carry through to end-to-end system behavior.
Artificial benchmarks
To evaluate Tidehunter in a controlled and repeatable setting, we built a series of specialized database load tests designed to approximate the access patterns observed in Sui. Rather than benchmarking isolated primitives, the goal was to exercise realistic mixes of inserts, deletes, point lookups, and iteration workloads that reflect how validators interact with persistent state.
The benchmark framework is database-agnostic: any storage engine implementing a small set of core operations can be plugged in and evaluated under identical load. Using this framework, we compared Tidehunter against RocksDB in multiple configurations, including RocksDB with and without a blob store. This allowed us to isolate the effects of write amplification, value placement, and indexing strategies across different designs.
Workloads are synthetically generated but parameterized to match Sui’s characteristics, including read/write ratios, key distributions, and value sizes. All benchmarks run on hardware that closely matches recommended Sui validator specifications, ensuring results are representative of production environments rather than idealized lab setups.
Across these workloads, Tidehunter consistently sustains higher throughput and lower latency while consuming significantly less disk write bandwidth than RocksDB. The difference is most pronounced under write-heavy and balanced read-write profiles, where reduced write amplification leaves substantially more IO capacity available for serving reads.
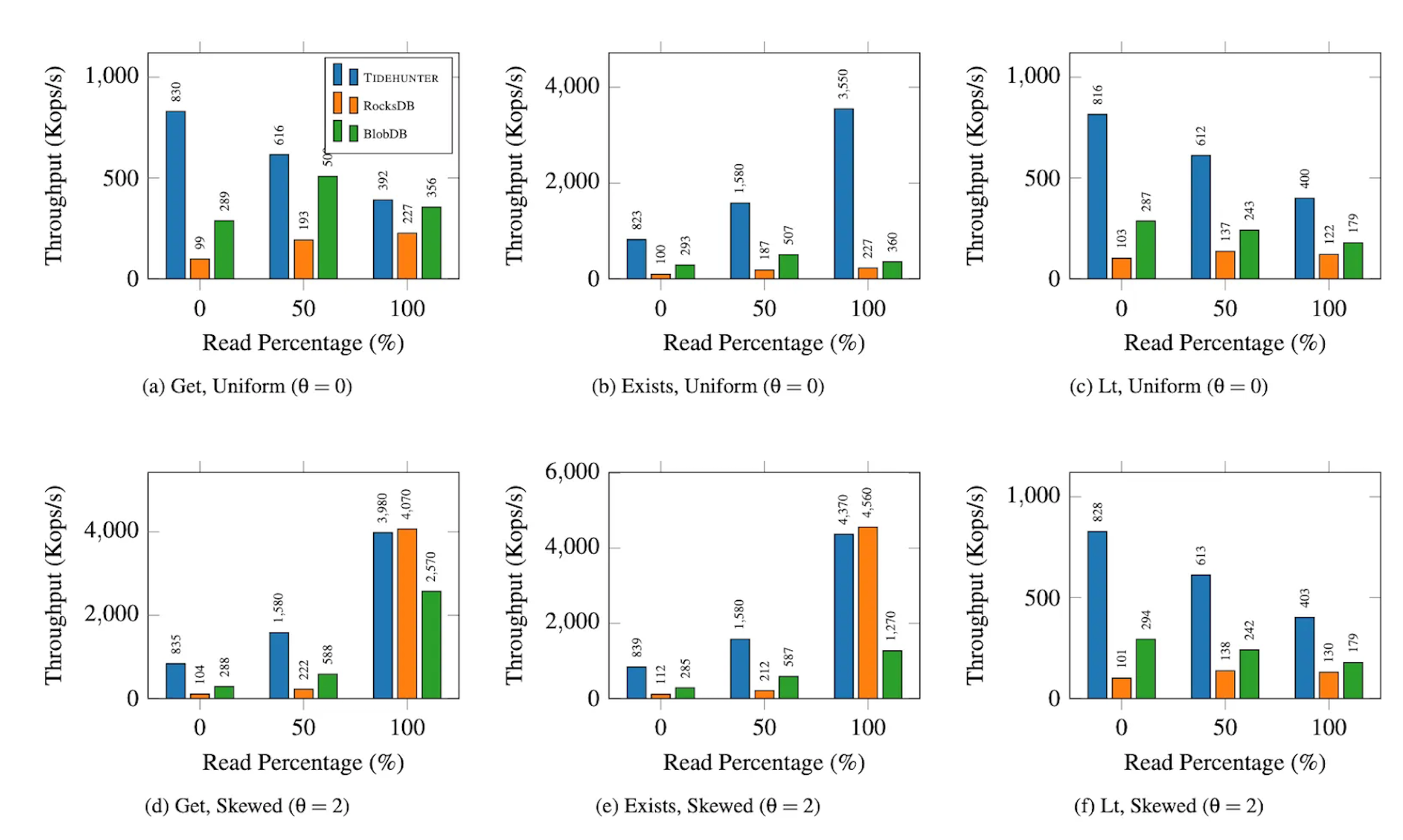
Sui validator benchmarks
To validate that these improvements translate to real-world behavior, we integrated Tidehunter directly into Sui and ran validator benchmarks under sustained transaction load.
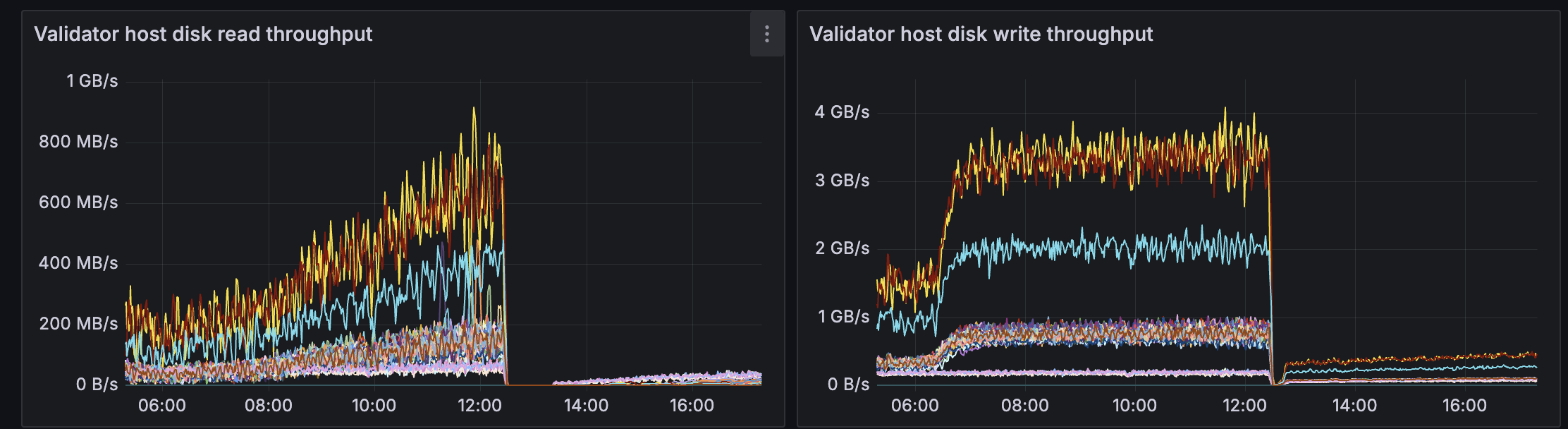
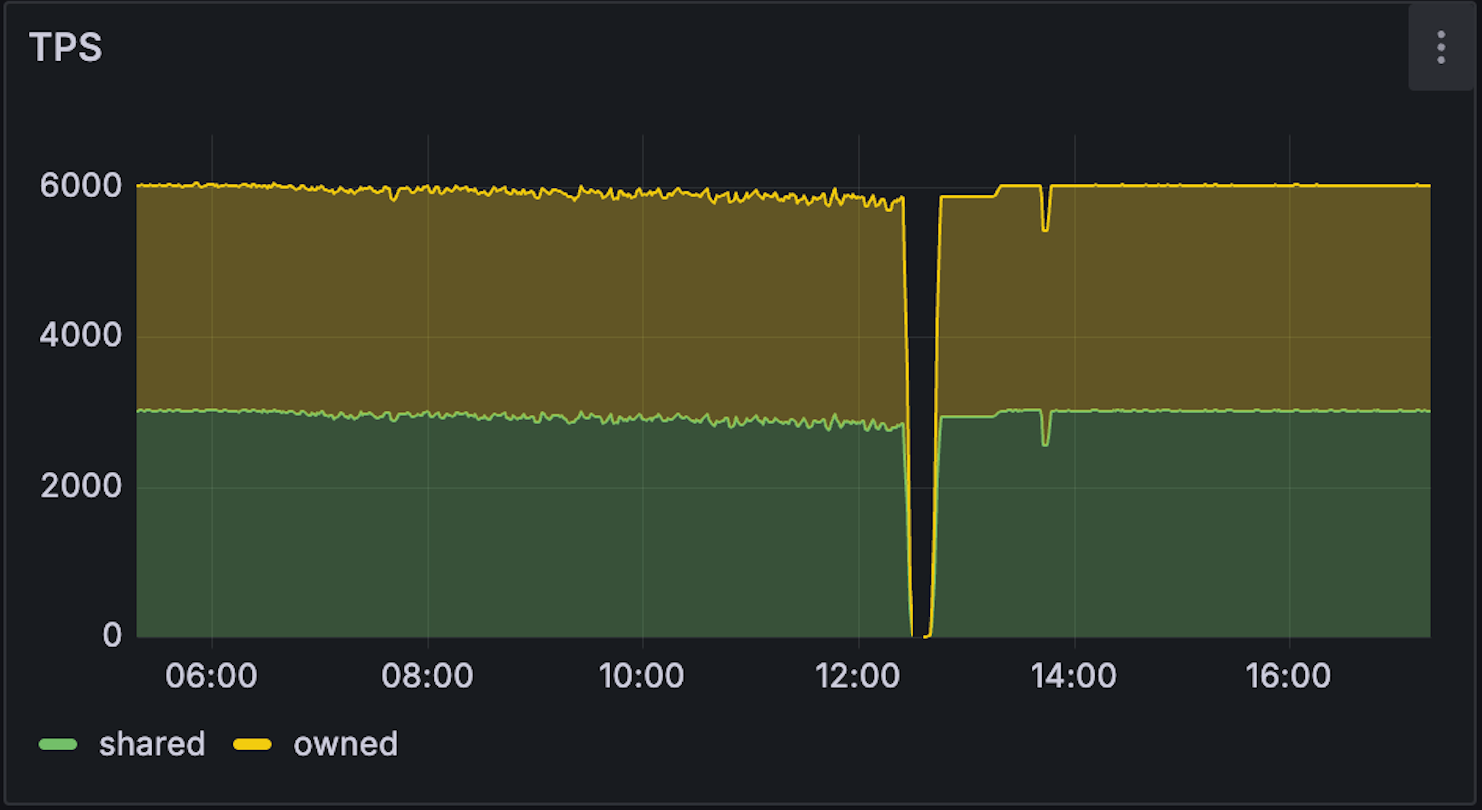
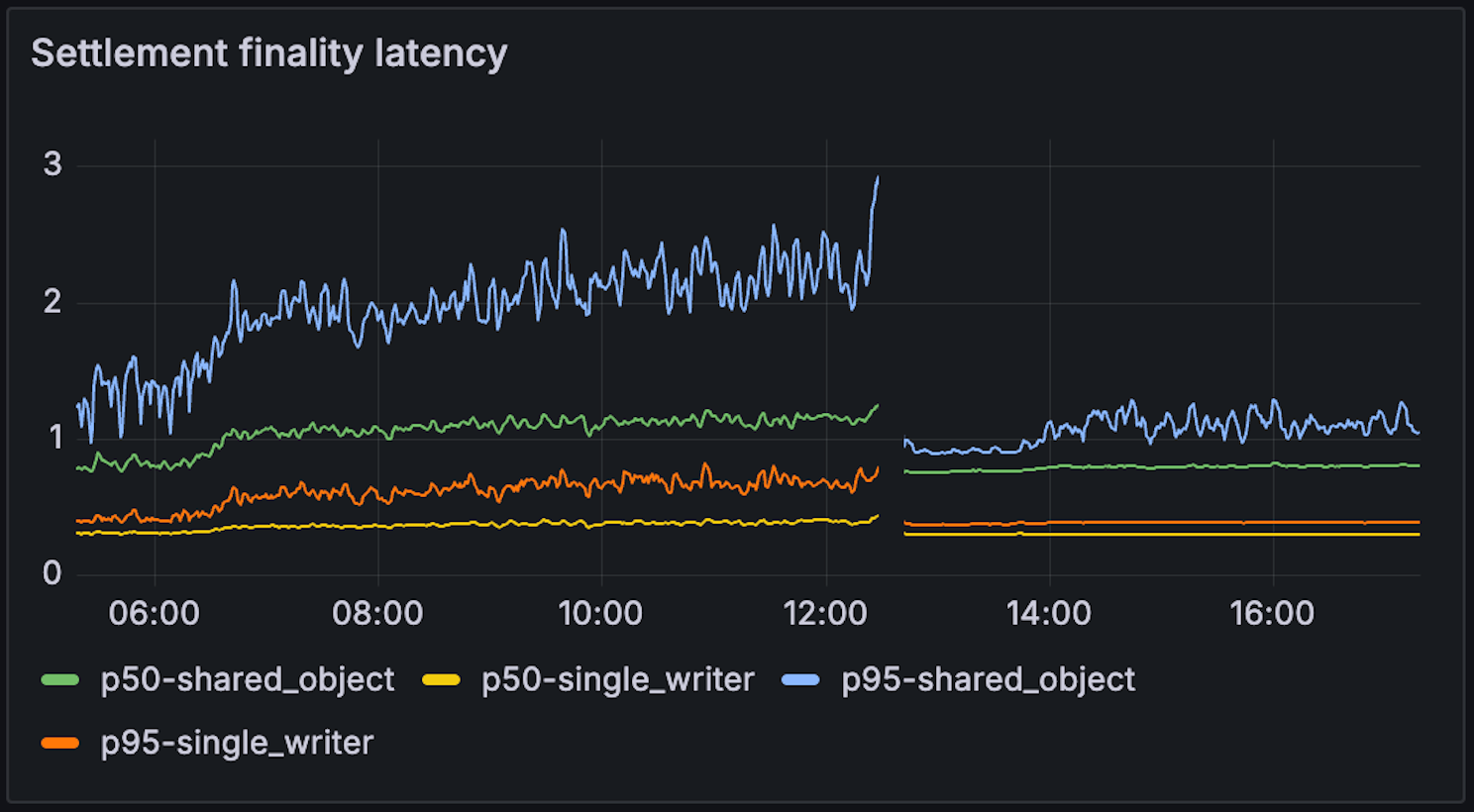
All validators started the experiment using RocksDB and switched to Tidehunter at the 12:30 mark. When running Sui with RocksDB, we observed noticeable performance degradation at moderate throughput levels, around 6,000 transactions per second, as disk utilization increased and latency began to climb. Under the same conditions, Tidehunter maintained stable throughput and lower latency, with reduced disk pressure and more consistent CPU utilization.
Side-by-side runs highlight clear differences in disk read and write throughput, sustained TPS, and settlement finality latency. In particular, Tidehunter avoids the IO saturation effects that trigger performance collapse in RocksDB-backed configurations under comparable load.
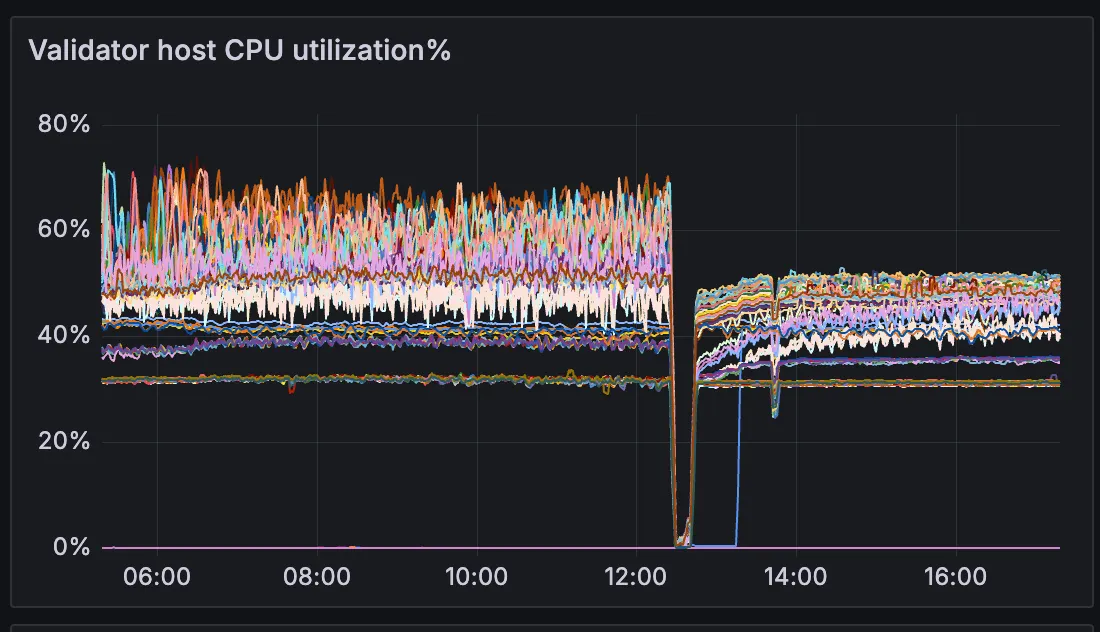
Looking ahead
Tidehunter is not an academic exercise. It is a practical response to the realities of operating a high-performance blockchain over the long term.
As throughput increases and workloads become sustained rather than bursty, storage efficiency becomes protocol-critical. With Tidehunter, we believe Sui is positioned ahead of that curve, with a storage foundation designed explicitly for the next phase of scale.
Tidehunter is designed for the next phase of blockchain scale, where sustained performance depends on storage efficiency.
More details, benchmarks, and rollout plans will follow.